字符编码
计算机中的所有数据都是以二进制的形式存储,字符也不例外。
字符编码是将字符映射为计算机可以处理的二进制数据的一种方式,建立现实世界文字、符号等与计算机中二进制数据的一一对应关系。 为计算机存储、传输和展示字符提供了标准。
计算机中的字符编码有很多种,常见的有 ASCII 字符集、Unicode 字符集、UTF-8 字符集等。
字符集和编码方式
字符集 是一个字符的集合,它定义了哪些字符可以使用,以及这些字符的唯一编号(即码点)。
字符集只描述字符本身以及每个字符对应的码点(通常是一个整数),它并不涉及这些字符对应的二进制数据以何种形式在计算机中存储。
编码方式 是将字符集中的字符转换为计算机可以存储或传输的二进制数据的规则。
编码方式规定了字符的编号(码点)应该如何转化为二进制,从而在计算机中存储或传输。 我们用字符集 Unicode ,编码方式 UTF-8 和 UTF-16 为例
- "中" 的
Unicode编码点是U+4E2D,在UTF-8中用 3 个字节0xE4B8AD表示,在UTF-16中用 2 个字节0x4E2D表示。
同一个码点在不同的编码方式中可能对应不同的二进制数据。
字符集
ASCII 字符集
ASCII 是最早的字符编码之一,制定于1960年代。用于表示基本的拉丁字母、数字、标点符号和控制字符。
因为其使用了 7 位二进制数,所以最多只能表示 128
由于其表示字符的数量限制,随着计算机的发展渐渐不能满足不同语言的字符需求,在 ASCII 的基础上通过扩充为 8 位二进制数形成了 EASCII 字符集。
由于 ASCII 码表ASCII 并没有严格规定 EASCII 的具体扩展内容,因此不同厂商、系统和地区可能对 128-255 范围的字符有不同的定义。 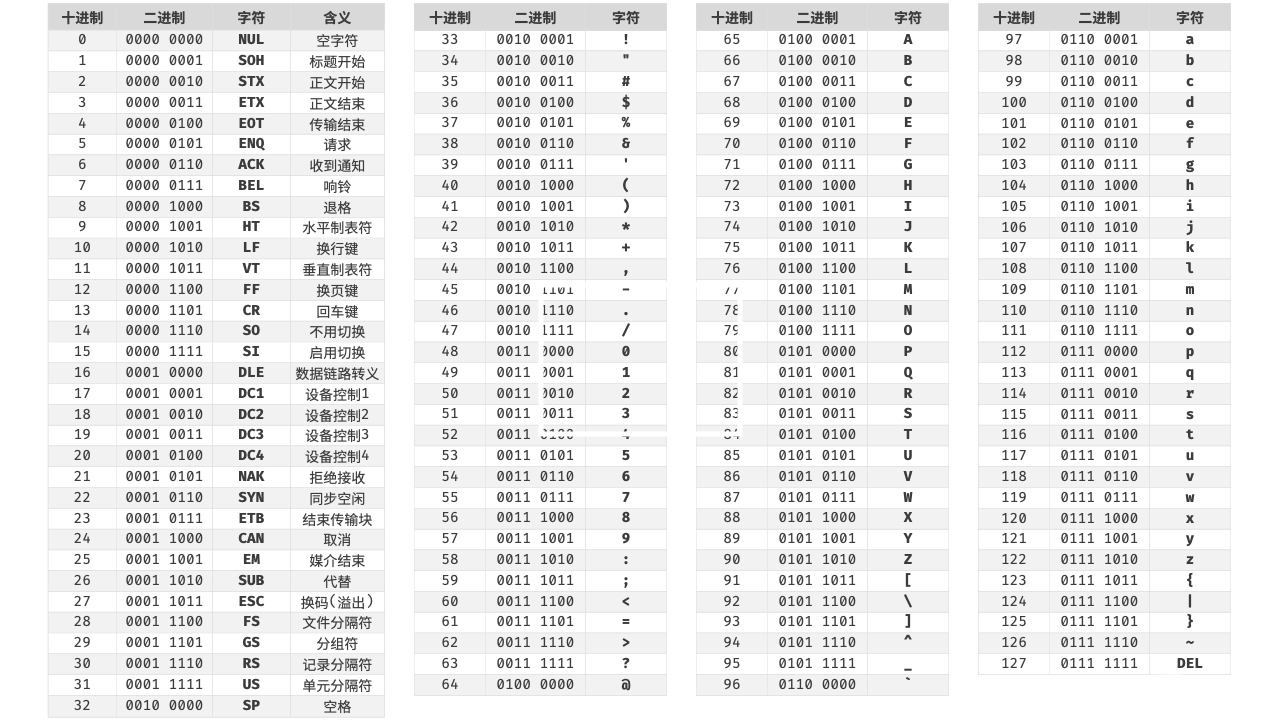
GBK 字符集
汉字的字符量过于庞大,所以 ASCII 字符集无法满足汉字的编码需求。为了解决这个问题,早期中国制定了 GB2312 字符集,收录了 6763 个常用汉字。
GBK 字符集是 GB2312 的扩展版本,收录了2万多个汉字,包括对简体、繁体中文和少数民族文字字符的支持,并增加了更多符号,同时兼容 GB2312。
NOTE
ASCII 和 GBK 这两个字符集略有特殊,他们属于较早期的字符标准,在规定了字符集的同时也规定了编码方式。
ASCII 是一种固定长度的编码方式,通常用 1 个字节来存储每个字符。
GBK 对于 ASCII 范围内的字符,同样使用与 1 个字节编码,对于扩展的汉字和符号,使用 2 个字节编码。
Unicode 字符集
由上述的字符集可以看出,不同的字符集对应的字符数量不同,而且字符集之间没有统一的规范,这就导致了不同的字符集之间的字符无法互相转换。 在使用不同的字符编码的计算机之间的数据交换时,同一个码点却代表了不同的文字,就会出现乱码的情况。
Unicode (统一码,又叫万国码)的提出旨在为全球所有语言的所有字符分配一个唯一的编号,解决历史上字符编码标准不统一、互不兼容的问题。
它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
自其发布以来,Unicode 不断扩展,目前最新版本 Unicode 15 收录了超过 15 万个文字字符,还包括技术符号、标点符号、表情符号等。
Unicode 定义了字符的编码点,但如何将这些编码点表示为计算机中的二进制数据,其本身没有规定。 为了将这些编码点转换为二进制数据,出现了多种编码方式,最常见的是 UTF-8、UTF-16 和 UTF-32。
编码方式
为了在尽可能多且正确表示字符的前提下,尽可能节省存储空间,不占用多余的字节数,产生了如下编码方式。
UTF-8
是一种 可变长度 的编码方式,使用 1 到 4 个字节来表示每个 Unicode 字符,根据字符的复杂性而变。是目前最广泛使用的编码方式,尤其在网络和网页中非常流行,
可以编码为 1 字节的字符
- 规则:将最高位设置为
0,其余 7 位设置为 Unicode 码点。 - 范围:对应
Unicode编码点为U+0000(0) 到U+007F(127)(即 ASCII 字符集)。
示例
字符 "A"(U+0041)在 UTF-8 中表示为 0x41(即 01000001)。
可以编码为 n 字节的字符(n > 1)
- 规则:将首个字节的高 n 位都设置为
1,第 n + 1 位设置为0。从第二个字节开始,将每个字节的高 2 位都设置为10。 其余所有位用于填充字符的Unicode码点,从低位开始填充,高位的 0 舍去。
示例
2 字节字符(对应范围 U+0080(128) 到 U+07FF(2047)):
- 格式:
110xxxxx 10xxxxxx - 示例:字符 "è"(
U+00E8,即拉丁小写字母 "è")- 二进制表示:
0000 0000 1110 1000 - 2 字节编码结果为:
C3 A8(即11000011 10101000)
- 二进制表示:
3 字节字符(对应范围 U+0800(2048) 到 U+FFFF(65535)):
- 格式:
1110xxxx 10xxxxxx 10xxxxxx - 示例:字符 "中"(
U+4E2D)- 二进制表示:
0100 1110 0010 1101 - 3 字节编码结果为:
E4 B8 AD(即11100100 10111000 10101101)
- 二进制表示:
4 字节字符(对应范围 U+10000(65536) 到 U+10FFFF(1114111)):
- 格式:
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx - 示例:字符 "😀"(
U+1F600)- 二进制表示:
0001 1111 0110 0000 0000 - 4 字节编码结果为:
F0 9F 98 80(即11110000 10011111 10011000 10000000)
- 二进制表示:
TIP
在 UTF-8 编码中,高 n 位的 1 的个数决定了字符的字节数,而后续字节的高 2 位都是 10,用于区分字符的不同字节。 10 起到了校验的作用,任何不是以 10 开头的后续字节都可以被立即识别为无效或错误。
这是因为 ASCII 中的所有字符用 UTF-8 表示都以 0 开头,而其码点之后的其他字符均为多字节字符,且至少以 11 开头。所以不存在以 10 开头的单字节字符。
UTF-16
是一种 固定长度 的编码方式,使用 2 个字节(16 位,即 U+0000 到 U+FFFF)来表示每个 Unicode 字符,不同于 UTF-8 的可变长度。
对于需要更多位的字符(即补充字符 U+10000 到 U+10FFFF),则使用一对 16 位(称为代理对)来表示。
其优势在于处理常用字符时更加高效,但对于补充字符则会增加复杂性,并且一定程度上浪费了存储空间。
UTF-32
是一种 固定长度 的编码方式,总是使用 4 个字节(32 位)来表示每个 Unicode 字符,即直接将 Unicode 码点转换为 32 位整数。
该种方式的编码访问非常简单,计算机处理字符时可以直接通过字符索引快速定位。 但是存储效率较低,尤其是在处理大量 ASCII 或其他较小字符集时,占用的空间相对较大,实际占用空间是 ASCII 所需空间的四倍。
锟斤拷
在使用 GBK 编码的中文系统中应该有不少用户见到过 锟斤拷 这个乱码。下面我们来解释一下原因。
在 Unicode 字符集中有一个专门用于表示 无法识别和展示的字符 的码点 U+FFFD(�),称为 替换字符。
该字符的 UTF-8 十六进制编码为 EF BF BD,二进制编码为 11101111 10111111 10111101。
当用户使用的编辑器修改文件并且以 UTF-8 编码保存时,如果遇到无法识别的字符,会将其替换为 U+FFFD(�)后保存。
如果文件中该字符出现了两次(EF BF BD EF BF BD)或更多,此时以 GBK 编码解析该文件时, 由于该编码是针对中文系统,每两个字节(16位)对应一个汉字,就会将其解析为 锟(EF BF) 斤(BD EF) 拷(BF BD)。